Wanted to introduce an agile architecture tip here.
People talk of agility all the while but a lot of best practices need to support agile such as all the things that devops brings to the table such as CD/CI and everything continuous. This means that there should be an ability to deploy code into production going through dev / test / pre prod / prod and everything in between that you can plan for releases in a product or solution. Unless an organization pays complete attention to getting the CI / CD practices upto date there can be no real agility as it is known the last mile in development is the place where the code gets pushed into production and there are many challenges right from developers saying the code works fine on our machines to the QA team and system test people having another opinion. Continuous development , continuous integration and continuous deployment makes all of this possible as it is quite possible to push code into production from development environments .
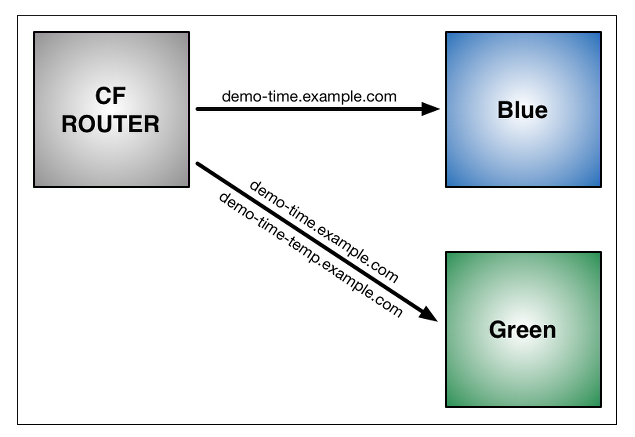
For agile practices like these you could use green blue deployments techniques. A little about the green blue technique
, it involves maintaining two environments one green and the blue environment where the exact production like environment is maintained end to end from the web server / app server , operating system and the database. This quite difficult to achieve end to end . So organizations make do with getting either the web server / app server replicated and have a common database. In that case using a router in between the traffic is routed to either the blue server or the green server.
ROUTER – —-> (test.sampletrail.com) > Blue Server ( let’s say this is the main server )
ROUTER ——> Establish temporary connectivity with the Green Server ( Standby server in case the main server goes down )
When you need to divert traffic to the green which has the latest code and patches while blue has the old code and server status. The blue can still be considered as the fall back server in case the green server gives up and is not able to handle the traffic and if found unsuitable or not stable. This option gives organizations the confidence to keep the system up and running and as they say is one of the ways in which the lights can be kept on. This is most often used in many RFC and RFPs from clients
There can be many edge cases there such as while the transition is happening to the green and then back to the blue what about the transactions that get posted via the green. If the database is unified then the challenges in this not wrecking the system can be limited based on the code in the application logic. But it is implied that the design level changes are taken care, to rollback or reconcile such transaction postings by means of application logic.
When the transition is happening only read only transactions are possible to ensure there is minimum changes to the consistency of the system. You can have this setup in a virtualized setup on the same physical machine or different machines.
Always keep the option of toggling between the blue green states so that it ensures complete flexibility in trying out quite and application patches with a lot of agility.
What are such practices that you use currently or want to be updated on do let me know ?
References :
https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
https://aws.amazon.com/blogs/compute/bluegreen-deployments-with-amazon-ecs/
https://martinfowler.com/bliki/BlueGreenDeployment.html
Success today requires the agility and drive to constantly rethink, reinvigorate, react, and reinvent. – Bill Gates
Picture Courtesy : Cloud Foundry blog

